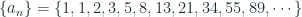A person from the thirteenth century, named Leonardo Pisano, known as Fibonacci depicted the following problem in his book Liber abaci: In an island two rabbits are placed. Two rabbits can reproduce after they are two months old. First two months there are one pair of rabbits, they reproduce after 2 months and produce another pair. The new born pair does not reproduce until they are 2 months old, the older pair produces another pair on the 4th month. Reproducing like this how many pairs of rabbits would be there in the island after n months, under the condition no rabbits die. The Fibonacci series is where each represents the number of rabbit pairs in the island on month n.
In this post we will see the obvious recursive solution, an iterative solution and a solution with which you can find the nth fibonacci number directly from an equation.
Fibonacci Series
The Fibonacci numbers are shown belows:
From the origin of the Fibonacci numbers and also studying the series it is clear that each number of the series is generated from the addition of the previous two numbers. Initially the first two number of the series are 1 , and that is given. That is the first two months there are 1 pair of rabbit in the island. Continue reading “Generating Fibonacci Numbers”→
This is another quick post about an unfinished (but working) software which I wrote around 8 years ago. It is an Intel 8085 microprocessor simulator, with a text based interface. The objective was to simulate the microprocessor, along with a minimal interface which closely resembles the microprocessor kit with the 7-segment displays, hex keyboard and minimal debugging features.
Quick story
In our undergraduate computer science degree, we had a few subjects on microprocessor architecture. One of the subjects focused on the Intel 8085 microprocessor architecture in great details, Intel 8086 architecture, interfacing, etc. Along with the detailed architecture, we also had to do some assembly code for 8085. It was fun because, we had to use a physical 8085 microprocessor kit with a hex keyboard and just those 7-segment displays.
8085 Microprocessor trainer kit
To write a code in the kit, you need to scan through the memory and enter the values of the assembled code. Who assembles it? We had to do that manually. We would have a table of all the instructions and the hex value for the op-code. More essentially it is very important to know the precise operations for each instruction. What operation it performs, which registers are accessed, what memory locations are accessed and how does it change the flags.
It gets more interesting (sometimes painful) when you first write your code in assembly in a white sheet of physical paper, then you refer the table and convert the assembly code to machine code, basically an entire page of hex values. Next, you get to your 8085 microprocessor kit, start from a memory location and keep on typing these hex values like a maniac. There were 8085 microprocessor kits which had some “debugging” facility, but essentially, if something goes wrong, it was extremely difficult to find, given our skills.
Although we were required to use the physical 8085 microprocessor kit in the exams, but for practice, we used 8085 microprocessor simulators. There are quite a few 8085 microprocessor simulators available. One of them was provided with one of the text books. There were simulators with text interface, some with text and some with nice GUI interfaces. I used one of them, the GNUSim8085. You can find an in depth review of GNUSim8085, which I wrote for OpenSource For You long ago, also posted here: Reviewing the GNUSim8085 (v1.3.7).
I personally did not like most of the simulators or the interfaces. All of them involved a lot of mouse-clicking, which slows you down a lot and does not reflect the actual 8085 trainer kit experience. There were a few which had full keyboard control, but somehow we felt that they were cumbersome. The Intel 8085 trainer kit experience was highly required inorder to timely and correctly finish the tasks given in the examination. The good thing was, I (and a few of my friends) knew exactly what I was looking for. Therefore I tried to make one … (drum roll) … Dirty8085.
It’s now mid October, there are 0 posts in 2017. Therefore I think it’s time to loosen up posting constraints and try make a bit more casual posts. For a start I will dig up one of the unfinished works. I will start with a quick overview of an old piece of tool (unmaintained) I wrote quite a few years ago. The tool caps the maximum CPU utilisation of a process from userspace without requiring root access. One instance of the process can cap multiple processes individually, in a group or it can also cap an entire process sub-tree. I intended to post about it in great detail, but this time I will keep it brief, and dig deeper in the next opportunity. Let’s get into it.
Motivation (from agony)
A few years ago, I was used to run different CPU intensive experiments on my old laptop, which would sometime run weeks. The CPU temperature used to go up to 95 Deg C. Sometimes it went upto 99 Deg C and then it used to throttle down the cores to get the temperature down. This is definitely not a healthy temperature, therefore I feared of hardware damage. The laptop had a metal case, which became so hot that it left red marks on my thighs. One time an entire chocolate bar melted into a pool of liquid chocolate (someone left it near the exhaust fan). Therefore it was time that I figure something out, such that I can run the experiments, but keep the laptop cool (relatively).
The obvious idea was to cap the CPU usage for the processes. An easy solution is to install a virtual machine and run the code inside the virtual environment. Note that, in my case nice does not work, as it does not help control how much of the CPU a processes utilises when it acquires it. I could have used cgroups, but I didn’t want to (I don’t know why). At that point of time I was feeling the need for Solaris Zones.
Essentially what I wanted is something portable in any *nix system, works completely from userspace and also does not need root privilege. Therefore I made a small tool which does in. It was written in C and POSIX compliant libraries.
Also note that, there is a similiar kind of tool called cpulimit, which I didn’t know existed when I wrote this. This tool works well too.
Given this situation, it was time to write something in-house … drum roll … CPULeash.
In this post, I will quickly show how you can use a debugger to hack poorly written or packaged code. More specifically, how to enter a wrong password but still get access. Before proceeding, I should be clear, that this is just a demonstration, and the programs out there in production (these days) will definitely not vulnerable to this method (if it is, then it is a shitty program). This is to demonstrate how you can change the execution path as you wish.
First I will show a simple code which prompts for a password to be set, then encrypts it using MD5 sum hash and salt and stores the hash in a file. Then it asks for the same password, reads the hash from the stored file and compares if the two entered passwords are same or not. Then I will show how to reverse engineer the executable file and enter the wrong password, but still make it think that we the correct password was entered. Continue reading “Hacking (Reverse engineering): Gaining access with wrong password”→
Long ago I posted about the WordPress.com stats API. WordPress.com Stats API. WordPress.com stores your blog’s raw visit stats which is available via your API key and the blog URL. Basically these stats are used to show the stats you see in your dashboard.
The older wordpress.com dashboard did not have much visualisations of the stats, but the new dashboard has introduced some more ways to see how your blog is doing. When I posted WordPress.com Stats API, there was absolutely no trace or documentation about the wordpress.com API. It seemed that even the guys in wordpress.com was not well aware about if such an API existed :D . (Check the post to know why).
At the previous post I just provided some guides on how to fetch the data. Recently I planned to write a quick implementation to fetch the stats from wordpress.com and therefore I am going to share the script. This is a quick and dirty implementation to demonstrate the stuff. I have also made a few processing on the incoming data and made a few plots. Most of which might not (will not) make much sense (especially the box plots), but it’s just for the baseline. Let’s proceed with the code. Continue reading “Using WordPress.com stats API”→
It’s been a long time since I posted here. Therefore I decided to dig out some quick and straightforward stuffs from my disk which I previously decided should’t be in this blog.
I have posted multiple trie and dictionary search based programs in C, C++ and Perl before Jumble Work Solver and Jumble Work Solver Again. This time (again!) it’s about a trie. Although this time there was a specific requirement from a group who needed to implement a trie based word distance counting for bangla language, therefore Unicode support. This was supposed to be modified more and plugged into a spelling correction for scanned OCR text in the Bengali language.
Initially I suggested that a ternary tree would be more appropriate as the memory cost for standard trie (not compressed) would be huge. Although, finally the decision was to go with plain and simple trie. I know it is mad, but this is what it is :D.
Also, before going into the implementation, I should note that there is an efficient implementation of Radix Tree present in libcprops library. Though which we won’t be using for this one. I would recommend you people to have a look into this library if you already haven’t seen it yet.
Let’s say, we have a word “hello” and a node with an array of pointers of length 26 representing each character of the English language, each of which indicates that if the ith character follows the character represented by this node. Therefore for this example “hello”, the head node’s array of pointers will have the location 7 pointing to another node, which will have the 4th location of the pointer pointing to another node, whose pointer array’s 11 th location will point to another node and so on. Note here the indexing starts from zero. When the word ends, then the next pointer can be pointed to a special terminal marker node, which can be common to all, and the node is marked as a terminal node. This is essential as a valid word can be a substring of another valid word, in which case the shorter would need to be decided. When another new word like “help” comes in, we will follow the same path upto “hel” created by the word “hello”, and as we find there are no pointer for “p” pointing to any node, a new node will be created as explained before. Continue reading “A wide character trie implementation”→
Have you ever thought how the computer is able to display the correct time after you power on the system? There is a component called the RTC in the computer which stores this date and time information when the computer is turned off.
I will talk about how to read/write the date and time and use other features of the RTC using command-line tools, Linux RTC driver and also a low level direct access to the RTC internal registers. Continue reading “An overview of the PC Real Time Clock (RTC)”→
It’s been a long time I have done any activity in this blog. I was going through some old stuffs and thought to post something. Today I will post a generic implementation for Fisher-Yates Shuffle.
Although you can get the Fisher-Yates algorithm from wiki, still I am briefly explaining it.
Let us assume that there is a array arr of length n. We need to find a uniformly random permutation of the elements of the array. One of the variations of the algorithm is as follows.
arr is an array of length n, where indexing starts from 0
i=n-1
while i>0
{
r = generate a random number between 0 and i (both inclusive)
swap the array elements arr[r] and arr[i]
i = i - 1
}
arr is now uniformly permuted
It has been a long time since a post in this blog. I thought to break this silence with a short post.
Several text editors in Linux environment like KWrite and GEdit that will store automatic temporary files ending with a ~ (tilde) character. Generally it is a default setting in most of the major distributions. Initially this feature annoyed me, as now you have twice the number of files in your directory, and often used rm *~ to clear out the files. Although it was annoying at the beginning, there are several cases it saved me. Continue reading “Respect the ~ files”→
This is a quick post on how to generate a process tree Linux (and *nix) operating systems.
The idea is the same, as in the previous posts: Finding overall and per core CPU utilization and Find process IDs of a running process by name. Read the information present in the /proc/ directory. To get which processes are running we can read the directories with numbers as their names in the /proc/ directory. To generate a process tree we need to establish a process child relationship within the running processes. Each process has a parent (the first generated process is an exception), and it is stored in the process table entry of that process. We need to fetch the parent process id for each running process inorder to establish the tree. Here’s the plan. Continue reading “Generate the process tree of a Linux system”→