
A person from the thirteenth century, named Leonardo Pisano, known as Fibonacci depicted the following problem in his book Liber abaci: In an island two rabbits are placed. Two rabbits can reproduce after they are two months old. First two months there are one pair of rabbits, they reproduce after 2 months and produce another pair. The new born pair does not reproduce until they are 2 months old, the older pair produces another pair on the 4th month. Reproducing like this how many pairs of rabbits would be there in the island after n months, under the condition no rabbits die. The Fibonacci series is 

In this post we will see the obvious recursive solution, an iterative solution and a solution with which you can find the nth fibonacci number directly from an equation.
Fibonacci Series
The Fibonacci numbers are shown belows:
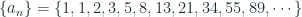
From the origin of the Fibonacci numbers and also studying the series it is clear that each number of the series is generated from the addition of the previous two numbers. Initially the first two number of the series are 1 , and that is given. That is the first two months there are 1 pair of rabbit in the island. Continue reading “Generating Fibonacci Numbers”
